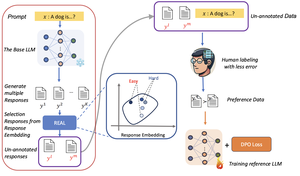
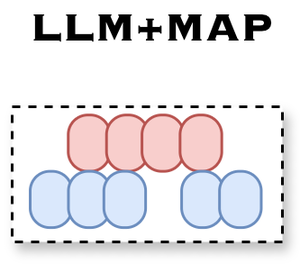
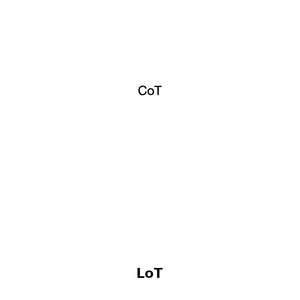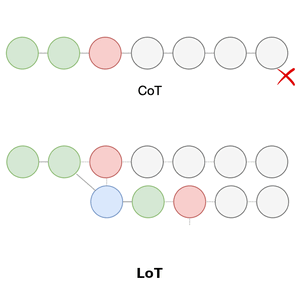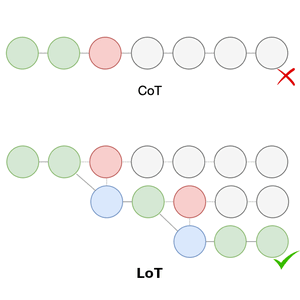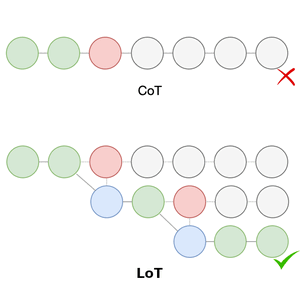
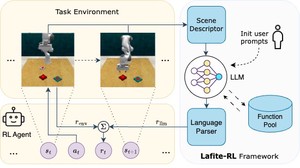
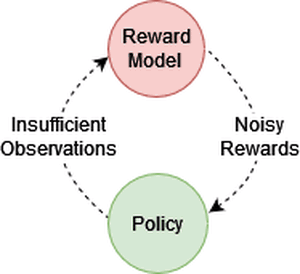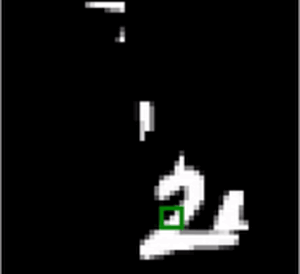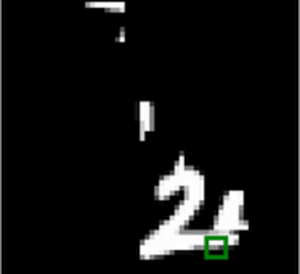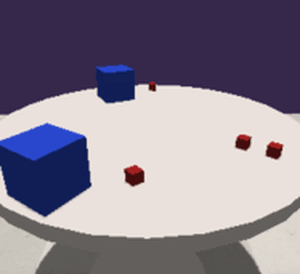
👋 Hi! I I defended my PhD on 08.10.2025‼️ Committee: Prof. Stefan Wermter (supervisor), Prof. Jianwei Zhang (deputy), and Prof. Sören Laue (chair).
I study embodied agents that explore, learn, and adapt autonomously, unifying reinforcement learning, world modeling, and large language models so agents can reason, acquire skills, and scale with minimal supervision. My long-term goal is to deliver robust, trustworthy systems that assist people in complex real-world settings.
Education
Ph.D. in Computer Science, 2025
University of Hamburg
M.Sc. in Signal Processing, 2018
University of Chinese Academy of Sciences
B.E. in Electronic Information Engineering, 2014
Xidian University
Interests
- Robotics / Embodied AI
- Reinforcement Learning
Work Experience
- Embodied AI Scientist, Alibaba, 2025–?
- AI Engineer, JD.COM, 2018–2020