Xufeng Zhao
Home
Publications
Posts
Experience
Awards & Grants
Contact
CV
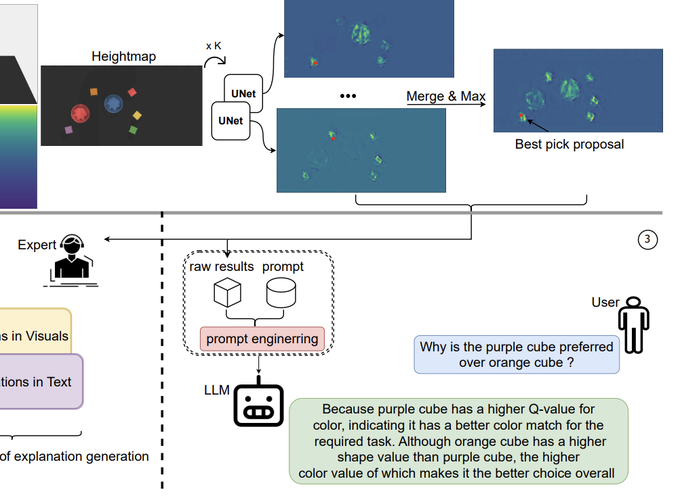
A Closer Look at Reward Decomposition for High-Level Robotic Explanations
Wenhao Lu
,
Xufeng Zhao
,
Sven Magg
,
Martin Gromniak
,
Mengdi Li
,
Stefan Wermter
January 2023
Go to Project Site
LLMs
RL
XAI
Robotics
Next
Internally Rewarded Reinforcement Learning
Previous
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Cite
×